数据集的划分,验证集参与训练了吗?
前言
在周志华老师的《机器学习》这本书中,我们知道训练机器学习以及深度学习的模型的时候,对数据集需要进行划分,通常划分成训练集和测试集,一般我们还会对训练集进行再划分一部分作为验证集。

一、验证集怎么用?
验证集参与训练了吗?
从《机器学习》这本书中,我们知道,训练集是拿来训练模型参数的,对于所有的训练集,训练一个epoch之后,我们会用验证集来测试一下模型在上面的性能,由于训练集和验证集的不可交性,所以在验证集上面的结果是有参考意义的。
但是重点是:
-
验证集并没有参与训练过程梯度下降过程的,狭义上来讲是没有参与模型的参数训练更新的。
- 但是广义上来讲,验证集存在的意义确实参与了一个“人工调参”的过程,我们根据每一个epoch训练之后模型在valid data上的表现来决定是否需要训练进行early stop,或者根据这个过程模型的性能变化来调整模型的超参数,如学习率,batchsize等等。
- 因此,我们也可以认为,验证集也参与了训练,但是并没有使得模型去overfit验证集
二、为什么需要测试集?
训练集就是用来训练参数的,说准确点,一般是用来梯度下降的。而验证集基本是在每个epoch完成后,用来测试一下当前模型的准确率,然后调整超参数。因为验证集跟训练集没有交集,因此这个准确率是可靠的。那么为啥还需要一个测试集呢?
这就需要区分一下模型的各种参数了。事实上,对于一个模型来说,其参数可以分为普通参数和超参数。在不引入强化学习的前提下,那么普通参数就是可以被梯度下降所更新的,也就是训练集所更新的参数。 另外,还有超参数的概念,比如网络层数、网络节点数、迭代次数、学习率等等,这些参数不在梯度下降的更新范围内。尽管现在已经有一些算法可以用来搜索模型的超参数,但多数情况下我们还是自己人工根据验证集来调。
那么就很明显了,我们还需要一个完全没有经过训练的集合,那就是测试集,我们既不用测试集梯度下降,也不用它来控制超参数,只是在模型最终训练完成后,用来测试一下最后准确率,确定模型的泛化能力强弱。
三、数据集的划分比例
一般情况而言划分比例: 数据量较小(传统机器学习) 没有验证集,训练集:测试集=7:3 有验证集,训练集:验证集:测试集=6:2:2
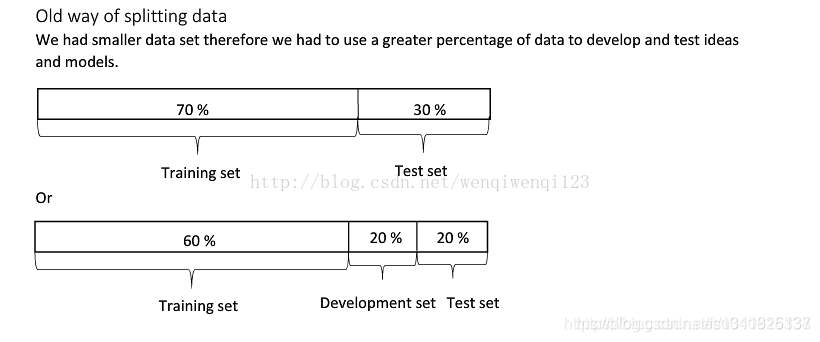
数据量较大(大数据划分)
假设有100W条数据,只需要拿出1W条来当验证集,1W条来当测试集,就能很好地work了。
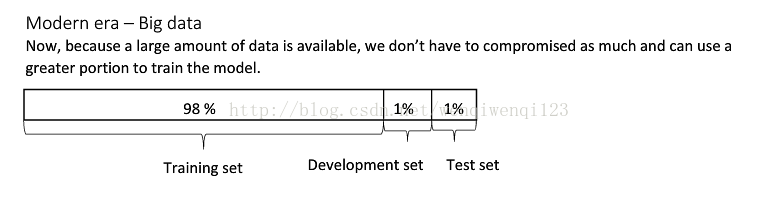 因此,在深度学习中若是数据很大,我们可以将训练集、验证集、测试集比例调整为98:1:1
因此,在深度学习中若是数据很大,我们可以将训练集、验证集、测试集比例调整为98:1:1