前言
由谷歌团队提出的预训练语言模型BERT近年来正在各大自然语言处理任务中屠榜(话说学者们也挺有意思的,模型名都强行凑个芝麻街的人物名,哈哈哈)。 BERT算法的最重要的部分便是Transformer的概念,它本质上是Transformer的编码器部分。 而Transformer是什么呢?transformer是永远的神,自从transformer使用了抛弃rnncnn的纯attention机制之后,各种基于transformer结构的预训练模型都如雨后春笋般雄起,而transformer中最重要就是使用了Self-Attention机制,所以本文会从Attention机制说起。
RNN模型解决seq2seq问题
首先我们举例子,讨论RNN模型如何解决机器翻译问题
我们以机器翻译问题作为基础,逐步讲解注意力机制及它的优缺点。首先,我们来看RNN模型是如何解决机器翻译问题的。这是一个Many to Many(Tx!=Ty)的Seq2Seq序列标注问题。

下图为RNN解决这一类输入序列和输出序列长度不等的序列标注问题的常用模型结构:
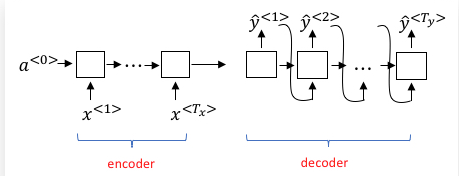
左边的encoder对输入序列建模,然后在网络的出口处提取最后一个时间步的激活值输出,得到输入序列的表示。编码器最后一个时间步的激活值输出因为走过了整个源文本序列,所以可以认为它蕴含了需要翻译的整个句子的信息。它的维度与RNN单元的隐藏层神经元数目一致。当然了,这里的RNN可以是深层的,但我们只以单隐藏层的RNN进行讲解。
右边的decoder部分可以看作是一个条件语言模型(Language Model,例如我们常见的AI写诗模型)。它的作用是通过编码器的表示作为输入,生成当前条件下最大概率的目标语言句子。它与常规的语言模型有两点不同:
- 语言模型零时刻的激活值为零向量,而机器翻译模型解码器的零时刻的激活值为编码器结尾的时间步激活输出。
- 语言模型为了保证生成句子的多样性,所以每个时间步的输出都是按照概率分布随机生成的。而机器翻译模型很明显需要翻译出最准确的结果,所以输出的序列应是全局最大概率的序列。
- 右边的decoder通过使用encode得到的表示和已经预测到的词作为输入,自回归的不断预测下一个词,但是rnn在预测当前词仅仅只用到了前一个cell的hidden state和前一个词作为输入。因此会有长依赖的序列问题。
顺便提一下,机器翻译问题中的全局最优解问题和CRF、HMM等常规机器学习的序列标注模型中类似吗,即解码策略,可以使用维特比算法来解,在对应的博客中都可以找到相应的说明。如果我们使用贪心算法,也就是greedy search,将可能陷入局部最优解中。 因此,特别地,我们发现,当词汇表规模很大时,即使是动态规划的维特比算法,其时空复杂度也会很高(时间复杂度:$O(MN^2)$,M为时序数,N为词汇表大小)。为了降低计算量,科学家们提出了集束搜索(Beam Search)的方法,即第一次输出时选取概率最高的B个单词,并将它们作为输入投入第二个时间步,第二次输出时仍然只选概率最高的B个单词……以此类推,到最后只会产生B条预测序列,我们选取概率最大的的作为最终的结果。这样做,其实就是在贪心搜索和维特比算法之间进行平衡,当B=1时,集束搜索退化成贪心算法,当B=N时,集束搜索演变成维特比算法。
RNN+Attention
上述RNN架构解决机器翻译会存在一些问题:
因为利用RNN解决机器翻译的时候,我们是将最后一个时间步的输出当做encode后的结果,所以可以认为它蕴含了需要翻译的整个句子的信息。 但是这样的理论在短序列中是有效的,在长序列中则会出现序列过长而无法catch到相对较远的特征,即产生信息瓶颈。 因此科学家在探索的过程中,引入了attention机制,对rnn的每一个时间步的输出学到一个注意力参数,从而对这些特征进行attention加权和,然后也作为decoder阶段的输入。 如下图所示,我们利用双向RNN对输入序列(x1,x2,x3)进行编码,然后对decoder端,我们在解码visits这个词的时候,这个时间步的输入有,
- 上一时刻的激活输出向量,
- 上一时刻的预测结果向量(即上一时刻的输出jane这个词),
- 还有与encode端的每一时间步的输出对应的attention的output(对x1,x2,x3的attention加权和,即对于每一个词的生成去学一个参数,因为不同的x对于不同的y生成的贡献是不一样的,因此需要attention)
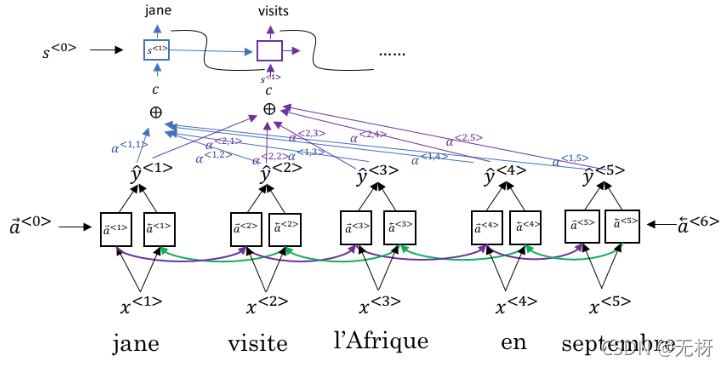
引入了attention之后的rnn为基础的机器翻译模型优点有: Attention机制的优点如下:
- 解决了传统RNN架构的“信息“瓶颈问题。
- 让解码器有选择性地注意与当前翻译相关的源句子中的词。
- 通过使编码器的各时序隐藏层和解码器各时序隐藏层直接相连,使梯度可以更加直接地进行反向传播,缓解了梯度消失问题。
- 增加了机器翻译模型的可解释性。
Transformer: yyds
尽管RNN+Attention的模型非常有效,但它同时也存在着一些缺陷。RNN最主要的缺陷在于:它的计算是有时序依赖的,需要用到前一个时间步或者后一个时间步的信息,这导致它难以并行计算,只能串行计算。而当今时代,GPU的并行化能够大大加速计算过程,如果不能够并行计算,会导致运算速度很低。
为了能够进行并行计算,又不需要多层迭代,科学家们提出了Transformer模型。它的论文题目很霸气《Attention is All You Need》。正如题目所说,Transformer模型通过采用Self-Attention自注意力机制,完全抛弃了传统RNN在水平方向的传播,只在垂直方向上传播,只需要不断叠加Self-Attention层即可。这样,每一层的计算都可以并行进行,可以使用GPU进行加速。
你可以使用Self-Attention层来完成任何RNN层可以做到的事情:
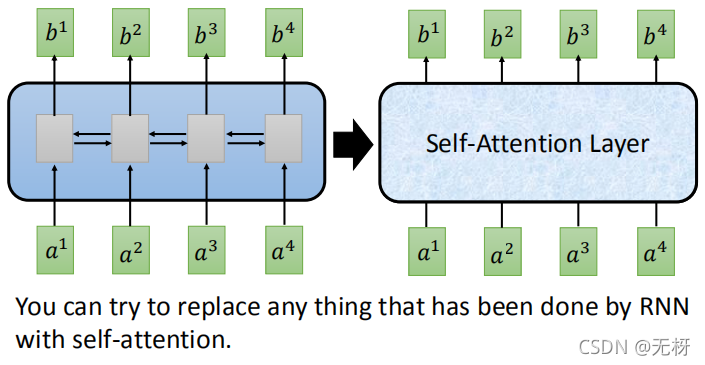
因为transformer用到了self-attention机制,我们首先对这个机制进行介绍:
Self-Attention
Self-Attention层的基本结构如下图所示:
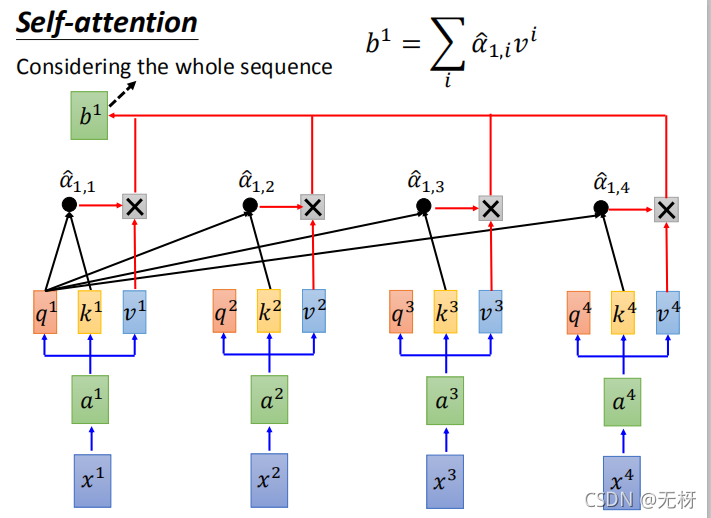
我们以计算$x_1$在输入到self-attention model之后的输出b1为例。
- 首先,我们以第一个单词的Word2Vec等预训练好的词向量作为输入x1,我们可以对其过一个全连接层或者MLP得到a1向量,可以看做是又做了一次嵌入(可能会改变维度)
- 接着,我们需要给定三个参数矩阵,分别为Wq、Wk、和Wv,通过三次矩阵乘法,我们从a1计算得到q1、k1、v1三个向量。(相当于三个分开的全连接层)。(需要注意,所有时序的计算共享上述四个参数矩阵,矩阵运算的时候所有时序都在矩阵中并行计算)其中,q向量称为query向量,用于匹配其它时序的k向量;k向量称为match向量,用于被其他时序的q向量匹配;v向量即为当前时序的要被抽取的信息。
- 然后,与上一节所说的Attention权重计算方式类似。我们先计算输出时序 1 对各输入时序 i 注意力得分α1,i,它是由时序1处的query向量q和各处的key向量k做点积操作后得到:α1,i=q1*ki
- 为了保证梯度稳定,我们还需要除以q和k共同维度的d的平方根,最后我们对注意力分数做概率转化,用softmax操作,得到a1对于k1k2k3k4….的所有注意力分数,然后和各时序的vi做加权求和,最终我们得到b1.
注意:如果是矩阵运算,最开始我们输入的是[x1,x2,x3,x4],经过嵌入之后得到维度为[seq_len,embed_size]的矩阵,seq_len是序列长度,而embed_size是token被嵌入之后的向量维度。
然后乘以Wq、Wk、和Wv,之后得到三个矩阵Q,K,V,然后通过Q和K算出注意力矩阵A。
这里的Q,K,V的维度都是[seq_len,embed_size],然后

对于每个词从attention得到的结果,我们将B=A*V得到self-attention部分输出的结果:B-size:[seq_len,embed_size]
Self-Attention的优点: 因为每个词都和周围所有词做attention,所以任意两个位置都相当于有直连线路,可捕获长距离依赖。 而且Attention的可解释性更好,根据Attention score可以知道一个词和哪些词的关系比较大。 易于并行化,当前层的Attention计算只和前一层的值有关,所以一层的所有节点可并行执行self-attention操作。 计算效率高,一次Self-Attention只需要两次矩阵运算,速度很快。
mult-head attention
transformer在模型结构中使用的mult-head的self-attention 我们来介绍一下 基本结构和self-attention相同,只是在运算的时候,分成多个头,然后分别并行的进行self-attention的计算,然后最后将输出的向量拼接到一起,这里不同的头会学习到不同层面的知识
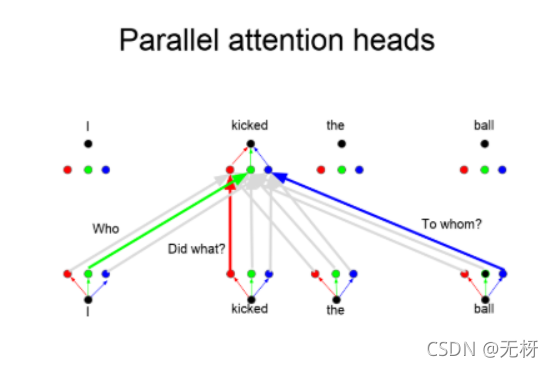
Multi-Head Self-Attention的优点:不同的head可以关注不同的重点,通过多个head可以关注到更多的信息。这有些相当于CNN中的不同filter。
此时,Self-Attention层还存在着一个问题:虽然此时通过注意力机制,可以有针对性地捕捉整个句子的信息,但是没有位置信息。 也就是说无论句子的结构怎么打乱,Transformer都会得到类似的结果。换句话说,Transformer只是一个功能更强大的词袋模型而已。
为了解决这个问题,研究人员中在编码词向量时引入了位置编码(Position Embedding)的特征。具体地说,位置编码会在词向量中加入了单词的位置信息,这样Transformer就能区分不同位置的单词了。
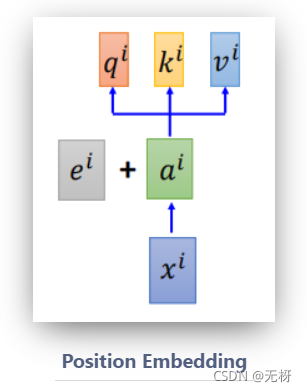
上述ei即为第 i 时刻输入的位置信息。它可以是学习而来的,也可以手工设置。
model structure
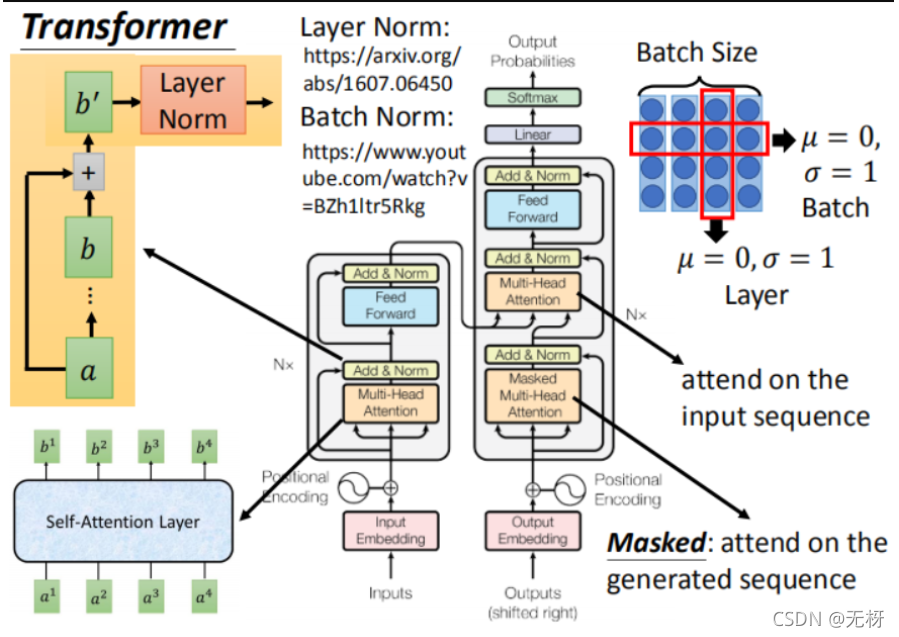
Encoder:
我们发现在我们将输入信息在输入encode部分之前,首先需要和每个位置token的position embedding进行拼接,作为mult-head-self-attention机制的输入,我们发现经过mult-head-self-attention机制输入输出的维度一样,然后这时我们需要经过一个add&norm层。
add指的是残差连接:
残差连接:
总结一下残差连接。 假如我们的输入为X,要得到的输出为H (X)。 那么我们可以通过 H = F (X) + X,转换为学习F。 等得到F的输出后,在此基础上加上X即可得H的输出。 在Transformer中,此时的F即是下图中的Multi-Head Attention和Feed Forward,我们再加上X即可得到需要的输出。
为什么要用残差网络,残差块之间因为有残差网络的原因,有类似于跳跃连接的效果,在网络加深的同时,梯度下降的也会训练的很好,可以解决梯度消失和退化问题,因为HX=Fx+x,会将链式求导中的指数级连乘导致梯度爆炸的情况进行改善。 而残差网络也可以解决网络退化问题,因为深层网络加入有些层是冗余的,那么将这些层学得恒等映射是很困难的,而对于残差网络来说,学HX=x是很容易的,只需要Fx拟合为0即可,即让什么都不做变得很简单。

那&norm中的norm的意思是归一化,transformer的归一化用的是层归一化。
Layer norm
Norm的意思就是在后面跟了一个归一化层。 论文原文中的公式为 LayerNorm (X + SubLayer (X)),SubLayer就是我上文说的F
残差路径上传来的向量和Self-Attention计算得到的向量相加后进行Layer-Normalization,即层标准化。Layer Norm对同一个样本同一层的所有神经元进行标准化,使它们满足标准正态分布 归一化分为:
- BatchNorm的主要思想是: 在每一层的每一批数据(一个batch里的同一通道)上进行归一化 。Batch Norm则是对Batch内不同样本的同一个神经元所有值进行标准化。
- Layer Norm对同一个样本同一层的所有神经元进行标准化,使它们满足标准正态分布,LayerNorm的主要思想是:是在每一个样本(一个样本里的不同通道)上计算均值和方差,而不是 BN 那种在批方向计算均值和方差!
- 为什么要使用层归一化:
- 一是解决梯度消失的问题,二是解决权重矩阵的退化问题 可以更好的解决梯度爆炸,梯度消失在深层网络中的问题,因为逐层进行了归一化,可以使得梯度传导的更稳定。
FFN
前馈神经网络,用在transformer中的作用是: FFN 相当于将每个位置的Attention结果映射到一个更大维度的特征空间,然后使用ReLU引入非线性进行筛选,最后恢复回原始维度。需要说明的是,在抛弃了 LSTM 结构后,FFN 中的 ReLU成为了一个主要的能提供非线性变换的单元。
至此,encode部分的三个模块我们都理清了, 在经过mult-head-self-attention以及残差连接和层归一化以及FFN之后我们得到的是每个词经过encode之后的表示,这个表示在影藏层中的维度可能不是初始输入维度,transformer在最中间的隐藏层的embedding size是2048,然后最后一层输出的embedding和输入的维度一样,最终我们得到的是[seq_len,embed_size]大小的矩阵。
Decoder
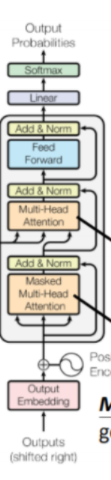
讲完encoder部分的数据处理过程,我们需要讲清楚decoder的结构。首先decoder的后面部分和encoder相同,但是刚开始会经过一个masked mult-head attention。后面经过的部分和encoder一样,但是不一样的是,在经过非mask-mult-head-self-attention的时候,输入的Q是decoder中masked self-attention输出的结果,而K和V却用的是encoder输出的向量乘以Wk,Wv得到的。 masked-self-attention 这里mask的作用,我们首先要知道,transformer用在seq2seq模型的时候,decoder序列的时候也是一个词一个词的自回归的生成,这个时候会用到一个casual attention的概念,就是每个词的生成只和他之前已经生成的词做attention运算。那么后面的词就需要mask掉,避免剧透未来信息。
我们以生成我,爱,机器,学习,翻译成<bos>,i,love,machine,learning,<eos>这个例子做生成过程来解释。 训练:
- 把“我/爱/机器/学习”embedding后输入到encoder里去,最后一层的encoder最终输出的outputs [10, 512](假设我们采用的embedding长度为512,而且batch size = 1),此outputs 乘以新的参数矩阵,可以作为decoder里每一层用到的K和V;
- 将<bos>作为decoder的初始输入,将decoder的最大概率输出词向量A1和‘i’做cross entropy(交叉熵)计算error。
- 将<bos>,”i” 作为decoder的输入,将decoder的最大概率输出词 A2 和‘love’做cross entropy计算error。
- 将<bos>,”i”,”love” 作为decoder的输入,将decoder的最大概率输出词A3和’machine’ 做cross entropy计算error。
- 将<bos>,”i”,”love “,”machine” 作为decoder的输入,将decoder最大概率输出词A4和‘learning’做cross entropy计算error。
- 将<bos>,”i”,”love “,”machine”,”learning” 作为decoder的输入,将decoder最大概率输出词A5和终止符</s>做cross entropy计算error。 那么并行的时候是怎么做的呢,我们会有一个mask矩阵在这叫seq mask,因为他起到的作用是在decoder编码我们的target seq的时候对每一个词的生成遮盖它之后的词的信息。 如下图:

在生成北这个词的时候,我们当前只能和<s>开始词去算attention。 在生成你这个词的时候,我们需要和<s>,北,京,欢,迎都算了attention。 因此decoder的流程基本都讲完了。 但是这里面有个问题,decoder是怎么用到encoder传过来的K和V的?
这里我们可以简单地解释一下,在decoder接收我们当前的targetlength长度作为输入时,是不会有停止词的,也就是decoder的输入时是<s>,北,京,欢,迎,你。而输出的对应位置(要算loss的相应位置的标准输出)是北,京,欢,迎,你,<e>。上图的横轴和纵轴正式如此。 对于我爱机器学习的例子而言,encoder的输入是我,爱,机器,学习 而decoder的输入是<bos>,i,love,machine,learning,decoder的输出是i,love,machine,learning,<eos>。懂了吗?等于每个位置的算loss的行为变成并行的了。
- 那我们在用到encoder部分的K和V的时候,我们知道这个K和V是encode输出[seq_len,embed_size]大小的维度矩阵乘以Wk和Wv得到的,K和V也是这个维度的,在我爱机器学习中的例子,seq_len=4(我,爱,机器,学习)。
- 而我们decoder的Q的产生是[target_len,embedd]维度的矩阵乘以Wq得到的,Q也是这个维度,target_len指的是decoder输入的句子长度,在我爱机器学习的例子中,target_len=5(输入是<bos>,i,love,machine,learning)。
这个时候我们要用decoder产生的Q去和encoder产生的K去算attention。
因此我们得到的attention矩阵是
d是embedd_size。因此我们的A的维度应该是,【target_seq,seq_len】大小的矩阵,这个时候我们用A乘以V(seq_len,embed_size)得到的矩阵维度是【target_seq,embed_size】也就是每个词位置预测的embedding。后面可以经过一个全连接层将embedding映射到vocab词库大小的一个向量,在经过softmax层得到预测的向量,训练阶段可以拿这个向量和对应位置的标准答案案算交叉熵的loss。这就是我们transformer在seq2seq任务中的训练方法啦!
在测试模型的时候,Test:decoder没有label,采用自回归一个词一个词的输出,要翻译的中文正常从encoder并行输入(和训练的时候一样)得到每个单词的embedding,然后decoder第一次先输入bos再此表中的id,得到翻译的第一个单词,然后自回归,如此循环直到预测达到eos停止标记