什么是KD 树? KD tree是分割k维数据空间的数据结构,主要用于多维数据的NNsearch
一、KD-tree是什么?
我们回顾一下,二叉查找树 其实KDTree就是二叉查找树(Binary Search Tree,BST)的变种。二叉查找树的性质如下: 1)若它的左子树不为空,则左子树上所有结点的值均小于它的根结点的值; 2)若它的右子树不为空,则右子树上所有结点的值均大于它的根结点的值; 3)它的左、右子树也分别为二叉排序树;
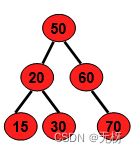 那如果我们要将一个k维度的二叉搜索树建立呢?
只不过我们对于当前节点的比较并不局限于一个值,而是一个K维度的向量
这时候我们的问题是:
那如果我们要将一个k维度的二叉搜索树建立呢?
只不过我们对于当前节点的比较并不局限于一个值,而是一个K维度的向量
这时候我们的问题是:
- 在哪一个维度划分左右子树?
- 怎么确保树两侧的节点尽量的平衡。
首先回答第一个问题: 划分左右子树的原则是:统计样本在每个维度上的数据方差,挑选出对应方差最大值的那个维度。数据方差大说明沿该坐标轴方向上数据点分散的比较开(后面会发现,选择方差大的维度主要是为了减少回溯时的代价,减少子树的访问)。这个方向上,进行数据分割可以获得最好的平衡
第二个问题怎么保证平衡: 给定一个数组,怎样才能得到两个子数组,这两个数组包含的元素 个数差不多且其中一个子数组中的元素值都小于另一个子数组呢?方法很简单,找到数组中的中值(即中位数,median),然后将数组中所有元素与中值进行 比较,就可以得到上述两个子数组。同样,在维度d上进行划分时,划分点(pivot)就选择该维度d上所有数据的中值,这样得到的两个子集合数据个数就基本相同了。
二、KD树的构建
(1)、在K维数据集合中选择具有最大方差的维度k,然后在该维度上选择中值m为pivot对该数据集合进行划分,得到两个子集合;同时创建一个树结点node,用于存储; (2)、对两个子集合重复(1)步骤的过程,直至所有子集合都不能再划分为止;
举个例子:
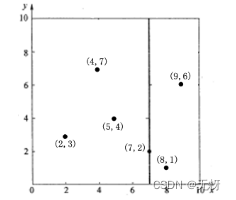
假设有6个二维数据点{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}数据点位于二维空间内(如下图中黑点所示)。kd树算法就是要确定图1中这些分割空间的分割线(多维空间即为分割平面,一般为超平面)。下面就要通过一步步展示kd树是如何确定这些分割线的。
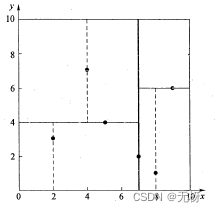
 发现x方向方差大于y方向
以x方向划分
根据x轴方向的值2,5,9,4,8,7排序选出中值为7,所以该node中的data = (7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于x轴的直线x = 7;
发现x方向方差大于y方向
以x方向划分
根据x轴方向的值2,5,9,4,8,7排序选出中值为7,所以该node中的data = (7,2)。这样,该节点的分割超平面就是通过(7,2)并垂直于x轴的直线x = 7;
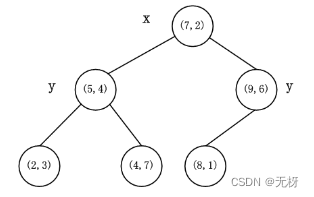
 然后对子空间分别递归同样的操作,KD树如下
然后对子空间分别递归同样的操作,KD树如下
三、Kd-Tree的最近邻查找
(1)将查询数据Q从根结点开始,按照Q与各个结点的比较结果向下访问Kd-Tree,直至达到叶子结点。 其中Q与结点的比较指的是将Q对应于结点中的k维度上的值与中值m进行比较,若Q(k) < m,则访问左子树,否则访问右子树。达到叶子结点时,计算Q与叶子结点上保存的数据之间的距离,记录下最小距离对应的数据点,记为当前最近邻点nearest和最小距离dis。 (2)进行回溯操作,该操作是为了找到离Q更近的“最近邻点”。即判断未被访问过的分支里是否还有离Q更近的点,它们之间的距离小于dis。 如果Q与其父结点下的未被访问过的分支之间的距离小于dis,则认为该分支中存在离P更近的数据,进入该结点,进行(1)步骤一样的查找过程,如果找到更近的数据点,则更新为当前的最近邻点nearest,并更新dis。 如果Q与其父结点下的未被访问过的分支之间的距离大于dis,则说明该分支内不存在与Q更近的点。 回溯的判断过程是从下往上进行的,直到回溯到根结点时已经不存在与P更近的分支为止。
举个例子:
查找点Q(2,4.5),以上述KD树为例
首先通过二叉搜索,径产生的搜索路径节点有<(7,2),(5,4),(4,7)>
这时候我们需要回溯
首先以(4,7)作为当前最近邻点nearest,计算其到查询点Q(2,4.5)的距离dis为3.202,然后回溯到其父节点(5,4),并判断在该父节点的其他子节点空间中是否有距离查询点Q更近的数据点。以(2,4.5)为圆心,以为3.202为半径画圆,如图7所示。发现该圆和超平面y = 4交割,即这里:|Q(k) - m|=|4.5 - 4|=0.5 < 3.202,因此进入(5,4)节点右子空间中去搜索。所以,将(2,3)加入到搜索路径中,现在搜索路径节点有<(7,2), (2, 3)>。同时,注意:点Q(2,4.5)与父节点(5,4)的距离也要考虑,由于这两点间的距离3.04 < 3.202,所以将(5,4)赋给nearest,并且dist=3.04。
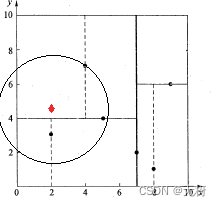 接下来,回溯至(2,3)叶子节点,点Q(2,4.5)和(2,3)的距离为1.5,比距离(5,4)要近,所以最近邻点nearest更新为(2,3),最近距离dis更新为1.5。回溯至(7,2),如图8所示,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,即这里:|Q(k) - m|=|2 - 7|=5 > 1.5。至此,搜索路径回溯完。返回最近邻点(2,3),最近距离1.5。
接下来,回溯至(2,3)叶子节点,点Q(2,4.5)和(2,3)的距离为1.5,比距离(5,4)要近,所以最近邻点nearest更新为(2,3),最近距离dis更新为1.5。回溯至(7,2),如图8所示,以(2,4.5)为圆心1.5为半径作圆,并不和x = 7分割超平面交割,即这里:|Q(k) - m|=|2 - 7|=5 > 1.5。至此,搜索路径回溯完。返回最近邻点(2,3),最近距离1.5。
总结
KD树就是也是一个通过用树这种数据结构加快搜索的时间效率的,但是随着k维度的上升,查询效率会下降,要求数据集的规模满足n的k次方,才能比较高的效率